[KR_OCR] 한국어 데이터셋(AI HUB)
기본적인 CRNN의 구조에 대한 파악이 끝난 후에
한국어 인식을 위한 한국어 데이터 셋을 사용하기 위한 준비.
Korea Sign Datasets
OCR 인식을 위한 한국 표지판 데이터 셋을 다운
- 어노테이션이 포함된 파일로 다운로드한다
- 데이터 다운로드 링크 : http://www.aihub.or.kr
AI 오픈 이노베이션 허브
AI 챗봇,안면인식 등 지능형 서비스 구현에 활용할 수 있는 지식베이스와 기계학습용 이미지 데이터를 제공합니다.
www.aihub.or.kr
>> 위의 주소로 들어가서 관광 카테고리에 가면 한국 표지판 데이터를 다운로드할 수 있다.
>> 다운로드한 뒤 압축을 푼 상태에서 'data/K-sign/' 경로 아래로 데이터를 넣는다
( 위 경로 아래에는 크롤링 데이터 / 고해상도 / 중 해상도 / 저해상도 각각의 파일에 이미지와 어노테이션이 있다)
K-Sign Dataset GTUtility 생성
- 현재 CRNN 모델에 잘 들어갈 수 있도록 전처리 과정이 필요하다
어노테이션( json 파일 ) 확인
import json
with open('data/K-Sign/HighQuality/K-SignNet_DS_Sign_Annotation_HighQuality.json',encoding='UTF8') as f:
ksign = json.load(f)>> encoding을 UTF8로 설정을 해주어야 에러 없이 JSON파일을 불러올 수 있다.
>> 가져온 제이슨 파일은 딕셔너리 타입니다.
>> ksign.keys()의 값은 이미지 파일의 이름에 뒤에 특정 숫자가 붙는다.
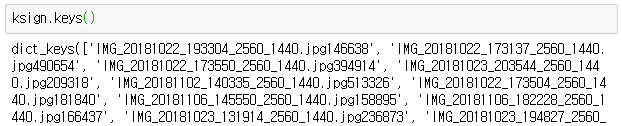
Key에 해당하는 Value를 확인
- 각 이미지에 해당하는 어노테이션 형식 확인

file_attributes : dataSource, imageSource, image_resolution, labeling 등 파일에 대한 info
filename : 해당 이미지 파일의 이름
regions : region_attributes(촬영한 지역에 정보)
: shape_attributes(데이터 박스의 좌표 값)
>> polygon 형태일 경우 : all_point_x [ x1, x2, x3, x4 ]와 all_point_y [ y1, y2, y3, y4 ] 값이 들어있다.
>> rect 형태일 경우 : box값으로 [ x, y, w, h ] 값이 들어있다
>> 텍스트 박스가 여러 개일 경우 regions안에 여러 개가 들어있다.
size : 사이즈 값이 있는데 이 값과 이미지 파일의 이름을 붙여서 key값으로 사용된다
box값은 rect 타입과 polygon 타입으로 구성.
if gt_type == "rect":
x = gt_data[img]['regions'][ann]['shape_attributes']['x']
y = gt_data[img]['regions'][ann]['shape_attributes']['y']
w = gt_data[img]['regions'][ann]['shape_attributes']['width']
h = gt_data[img]['regions'][ann]['shape_attributes']['height']
box = np.array([x,y,x+w,y,x+w,y+h,x,y+h], dtype=np.float32)
else gt_type == "polygon":
xlist = gt_data[img]['regions'][ann]['shape_attributes']['all_points_x']
ylist = gt_data[img]['regions'][ann]['shape_attributes']['all_points_y']
if len(xlist)!= 4:
continue
xy= []
xy = [xlist[0]]+ [ylist[0]]+ \
[xlist[3]]+ [ylist[3]]+ \
[xlist[2]]+ [ylist[2]]+ \
[xlist[1]]+ [ylist[1]]
box = np.array(xy, dtype=np.float32)
else:
continue>> 데이터의 형태에 따라 전처리해주는 방식이 다르다.
>> 일단 최종 box에 들어갈 값은 박스의 4개의 (x, y) 값이다
>> x, y 값은 왼쪽 위 > 오른쪽 위 > 오른쪽 아래 > 왼쪽 아래 점 순서로 바꿔준다
(현재 COCO-Text의 boxes의 값과 동일하게 맞춰주기 위해서)
boxes 값을 정규화
- boxes 값의 x값들은 이미지의 width로 나눠준다 (0과 1 사이로 맞춰줌)
- boxes 값의 y값들은 이미지의 height로 나눠준다 (0과 1사이로 맞춰줌)
boxes = np.asarray(boxes)
boxes[:,0::2] /= 2560
boxes[:,1::2] /= 1440
최종 아웃풋을 COCO-Text의 변수 값들과 동일한 형태로 맞춘다
- image_names : 이미지 파일 명
- data : bbox의 값 [ x1, y1, x2, y2, x3, y3, x4, y4 ] 8개의 배열로 들어간다
- text : label text 값이 들어간다
- image_path : 이미지 파일이 있는 경로
최종 코드 확인
data_KSign.py
import numpy as np
import json
import os
from ssd_data import BaseGTUtility
class GTUtility(BaseGTUtility):
"""
Utility for Korean-text dataset.
"""
def __init__(self, data_path, quality = 'high', polygon=True, only_with_label=True):
test = False
self.data_path = data_path
gt_path = data_path
image_path = data_path
#image_path = os.path.join(data_path, 'train')
self.gt_path = gt_path
self.image_path = image_path
self.classes = ['Background', 'Text']
self.image_names = []
self.data = []
self.text = []
if quality == 'high':
with open(os.path.join(gt_path, 'K-SignNet_DS_Sign_Annotation_HighQuality.json'),encoding='UTF8') as f:
gt_data = json.load(f)
elif quality =='mid':
with open(os.path.join(gt_path, 'K-SignNet_DS_Sign_Annotation_MidQuality.json'),encoding='UTF8') as f:
gt_data = json.load(f)
elif quality == 'low':
with open(os.path.join(gt_path, 'K-SignNet_DS_Sign_Annotation_LowQuality.json'),encoding='UTF8') as f:
gt_data = json.load(f)
else:
print('quality 입력!!')
for img in gt_data.keys():
image_name = gt_data[img]['filename']
#print(image_name)
boxes = []
text = []
for ann in range(len(gt_data[img]['regions'])):
gt_type = gt_data[img]['regions'][ann]['shape_attributes']['name']
if gt_type == "rect":
x = gt_data[img]['regions'][ann]['shape_attributes']['x']
y = gt_data[img]['regions'][ann]['shape_attributes']['y']
w = gt_data[img]['regions'][ann]['shape_attributes']['width']
h = gt_data[img]['regions'][ann]['shape_attributes']['height']
#box = np.array([x,y, x+w, y+h], dtype=np.float32)
#box = np.array([x,y,x,y+h,x+w,y+h,x+w,y], dtype=np.float32)
box = np.array([x,y,x+w,y,x+w,y+h,x,y+h], dtype=np.float32)
elif gt_type == "polygon": # for 4points
xlist = gt_data[img]['regions'][ann]['shape_attributes']['all_points_x']
ylist = gt_data[img]['regions'][ann]['shape_attributes']['all_points_y']
if len(xlist)!= 4:
continue
xy= []
xy = [xlist[0]]+ [ylist[0]]+ \
[xlist[3]]+ [ylist[3]]+ \
[xlist[2]]+ [ylist[2]]+ \
[xlist[1]]+ [ylist[1]]
#여기서 박스의 모양:
#가장 왼쪽 상단 > 오른쪽 상단 > 오른쪽 하단 > 왼쪽 하단 순서로 이동.
'''for x, y in zip(xlist, ylist):
xy = xy + [x] + [y]'''
box = np.array(xy, dtype=np.float32)
else:
continue
if 'annotation_kr' in gt_data[img]['regions'][ann]['region_attributes'].keys():
txt = gt_data[img]['regions'][ann]['region_attributes']['annotation_kr']
else:
if only_with_label:
continue
else:
txt = ''
boxes.append(box)
text.append(txt)
if len(boxes) == 0:
#print("No Bounding Box !")
continue
boxes = np.asarray(boxes)
#print(boxes.shape)
boxes[:,0::2] /= 2560
boxes[:,1::2] /= 1440
boxes = np.concatenate([boxes, np.ones([boxes.shape[0],1])], axis=1)
self.image_names.append(image_name)
self.data.append(boxes)
self.text.append(text)
self.init()
if __name__ == '__main__':
gt_util = GTUtility('data/K-SIGN/', validation=False, polygon=True, only_with_label=True)
import pickle
file_name = 'gt_util_ksigntext.pkl'
print('save to %s...' % file_name)
pickle.dump(gt_util, open(file_name,'wb'))
print('done')
print(gt_util.data)>> 위 GTUtility를 호출할 때 파라미터로 quality와 이미지 데이터가 있는 경로를 준다.
>> quality = 'high' / 'mid' / 'low' 중 하나를 주면 된다.
Json파일을 Pickle파일로 변경
위에서 만든 클래스를 import 한다.
from data_KSign import GTUtility
3가지 퀄리티 각각의 GTUtility 객체를 생성한다.
gt_util_high = GTUtility('data/K-Sign/HighQuality/', quality='high')
gt_util_mid = GTUtility('data/K-Sign/MidQuality/', quality='mid')
gt_util_low = GTUtility('data/K-Sign/LowQuality/', quality='low')- 위에서 생성한 객체를 print() 한다.
- 생성된 객체에 대한 간략한 summary()를 확인할 수 있다.
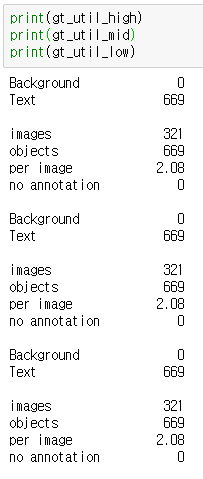
위에서 생성한 객체를 이용해 피클 파일 생성
#HighQuality 피클파일
file_name = 'gt_util_ksign_high.pkl'
pickle.dump(gt_util_high, open(file_name,'wb'))
#MidQuality 피클파일
file_name = 'gt_util_ksign_mid.pkl'
pickle.dump(gt_util_mid, open(file_name,'wb'))
#LowQuality 피클파일
file_name = 'gt_util_ksign_low.pkl'
pickle.dump(gt_util_low, open(file_name,'wb'))>> pickle.dump(객체, open(파일명, 'wb')를 하면 피클 파일이 생성된다.
추후에 생성한 피클을 로딩할 때
import os
import pickle
from data_cocotext import GTUtility
#HighQuality
file_name1 = 'gt_util_ksign_high.pkl'
with open(file_name1, 'rb') as f:
gt_util_high = pickle.load(f)
#MidQuality
file_name2 = 'gt_util_ksign_mid.pkl'
with open(file_name2, 'rb') as f:
gt_util_mid = pickle.load(f)
#LowQuality
file_name3 = 'gt_util_ksign_low.pkl'
with open(file_name3, 'rb') as f:
gt_util_low = pickle.load(f)>> 위와 같은 방식으로 피클 파일을 로드시키면 된다.