[OCR] CRNN Model_기본 구조
<CRNN모델의 backbone역할을 하는 model에 대한 function>
-
backbone 역할을 하는 함수 : 논문에서 언급한 대로 VGG-16 모델 구현해서 사용.
- CNN Layer + LSTM(RNN) Layer
-
CNN Layer의 마지막의 2개의 Fully-Connected Layer 층은 CNN층으로 변경한다
-
RNN부분에서 LSTM을 사용하고 싶으면 gru=False로 주고, GRU를 사용할 때는 gru=True
1> CRNN parameter
- Input_shape : ( 256, 32, 1 )
- num_classes : 87 --> 라벨로 사용되는 클래스 수
2> CRNN Model output_shape : (학습과 예측의 모델이 각각 존재한다)
Model Architecture : CNN(6) + RNN(LSTM)(2) + FC(1) + Activation(softmax) = x
- model_train : Model(inputs=[image_input, labels, input_length, label_length], outputs=ctc_loss)
>> output shape : ( None, 1 )
>> 학습 모델의 경우 인풋인자가 4개로 늘어나고, 아웃풋 값이 ctc_loss를 적용한 값이 나온다.
- model_pred : Model(image_input, x)
>> Model의 output은 softmax를 통과하고 나온다.
>> output shape : ( None, 62, 87 )
3> Model.summary() : 각각 모델에서 공통으로 가지는 부분(model_prediction과 동일)
>> Input : ( None, 256, 32, 1 ) : (샘플 갯수, width, height, channel)
>> Conv1_1 * MaxPooling : ( None, 128, 16, 64 ) : 128 * 16 크기의 feature map 64개 생성
>> Conv2_1 * MaxPooling : ( None, 64, 8, 128) : 64 * 8 크기의 feature map 128개 생성
>> Conv3_1 * Conv3_2 * MaxPooling : ( None, 64, 4, 256) : 64 * 4 크기의 feature map 256개 생성
>> Conv4_1 * BatchNormalization : ( None, 64, 4, 512) : 64 * 4 크기의 feature map 512개 생성
>> Conv5_1 * BatchNormalization * MaxPooling: ( None, 64, 2, 512) : 64 * 2 크기의 feature map 512개 생성
>> Conv6_1 : ( None, 62, 1, 512 ) : 64 * 1 크기의 feature map 512개 생성
>> Reshape : ( None, 62, 512 ) : reshape(-1, 512)로 모양을 변경한다.
>> Bidirectional LSTM * Bidirectional LSTM : ( None, 62, 512 )
>> Dense : (None, 62, 87)
>> Softmax : (None, 62, 87)
**위의 기본 구조는 model_prediction 할 때 사용하고,
Model_Train 시킬 경우에는 기존 이미지 인풋에 3개의 인풋이 더 추가되고 아웃풋 값이 ctc loss 로 바뀐다.
아래에 차례로 2개의 모델의 summary()를 참고
< Model_Train >
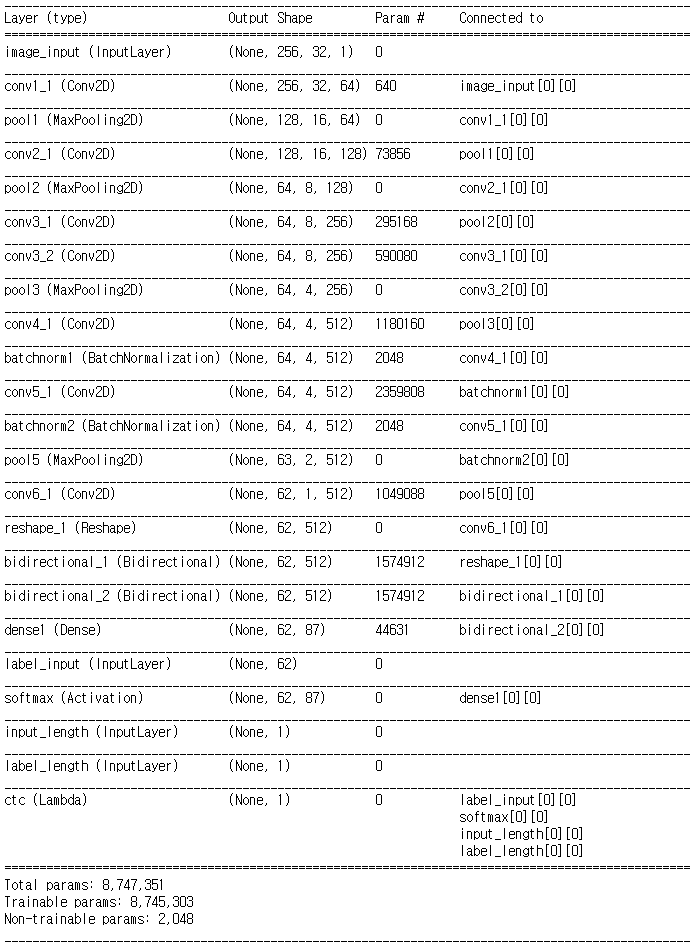
<Model_prediction>

4> 실제 모델 코드
ssd_detectors / crnn_model.py
def CRNN(input_shape, num_classes, prediction_only=False, gru=False):
"""CRNN architecture.
# Arguments
input_shape: Shape of the input image, (256, 32, 1).
num_classes: Number of characters in alphabet, including CTC blank.
# References
https://arxiv.org/abs/1507.05717
"""
act = 'relu'
# KERAS API를 사용한 모델 구현
x = image_input = Input(shape=input_shape, name='image_input')
x = Conv2D(64, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv1_1')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), name='pool1', padding='same')(x)
x = Conv2D(128, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv2_1')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), name='pool2', padding='same')(x)
x = Conv2D(256, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv3_1')(x)
x = Conv2D(256, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv3_2')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(1, 2), name='pool3', padding='same')(x)
x = Conv2D(512, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv4_1')(x)
x = BatchNormalization(name='batchnorm1')(x)
x = Conv2D(512, (3, 3), strides=(1, 1), activation=act, padding='same', name='conv5_1')(x)
x = BatchNormalization(name='batchnorm2')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(1, 2), name='pool5', padding='valid')(x)
x = Conv2D(512, (2, 2), strides=(1, 1), activation=act, padding='valid', name='conv6_1')(x)
x = Reshape((-1,512))(x)
if gru:
x = Bidirectional(GRU(256, return_sequences=True))(x)
x = Bidirectional(GRU(256, return_sequences=True))(x)
else:
x = Bidirectional(LSTM(256, return_sequences=True))(x)
x = Bidirectional(LSTM(256, return_sequences=True))(x)
x = Dense(num_classes, name='dense1')(x)
# output은 softmax함수를 사용하여 라벨에대한 확률값이 나온다.
x = y_pred = Activation('softmax', name='softmax')(x)
#모델을 정의 : Model(input, output)
model_pred = Model(image_input, x)
# train모델이아닌 preiction 모델의 output은 softmax activation을 적용한 값
if prediction_only:
return model_pred
#최대 글자수
max_string_len = int(y_pred.shape[1])
# CTC LOSS 함수 정의
def ctc_lambda_func(args):
labels, y_pred, input_length, label_length = args
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
# CTC LOSS를 계산할때 사용하는 INPUT 정의
labels = Input(name='label_input', shape=[max_string_len], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
# Lambda를 사용하여 ctc loss 구한다
ctc_loss = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([labels, y_pred, input_length, label_length])
# 최종 학습모델의 인풋은 4가지이고, 아웃풋은 ctc loss 값
model_train = Model(inputs=[image_input, labels, input_length, label_length], outputs=ctc_loss)
return model_train, model_pred