[Elasticsearch] 실전 쿼리 사용법
이번 포스팅은 엘라스틱을 사용하면서 필요한
쿼리 문법 사용에 관한 포스팅입니다.
1. 인덱스는 유지, 안의 document를 모두 삭제하는 쿼리
POST [인덱스이름]/_delete_by_query
{
"query": {
"match_all": {}
}
}
- 위와 같이 하면, 생성한 인덱스와 매핑은 유지되면서, 안에 적재한 데이터가 삭제된다
- 삭제는 주의, 또 주의해야함
>> 아래는 command 버전 명령어
curl -X POST "localhost:9200/[인덱스이름]/_delete_by_query?conflicts=proceed&pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}'
2. 인덱스 삭제
DELETE [인덱스이름]- 인덱스와 매핑정보, 안에 document까지 모든게 삭제 됨
>> 아래는 command 버전 명령어
curl -X DELETE "localhost:9200/인덱스이름?pretty"
3. 벌크로 데이터를 넣을 때
POST _bulk
{"create" : {"_index" : "2nd_contents","_type" : "_doc", "_id" : "100"}}
{"id" : "316", "set_id" : "DEMO", "a_id" : 1948, "cd_id" : 90,"c_key" : "53b64f39745","memo_s" : null,"g_key1" : "1948-90","h_key2" : "0-t0703","place" : null,"p_day" : "1970-01-01 00:00:00"}
{"create" : {"_index" : "2nd_contents_v2","_type" : "_doc", "_id" : "101"}}
{"id" : "317", "set_id" : "DEMO", "a_id" : 1948, "cd_id" : 90,"c_key" : "f39745","memo_s" : null,"g_key1" : "1948-90","h_key2" : "0-t0703","place" : null,"p_day" : "1970-01-01 00:00:00"}
- bulk로 데이터 삽입 시 꼭 주의 할 점은 인덱스 관련 명령어 한줄, 데이터 입력 관련 한줄 이렇게 입력해야함
- '\n'으로 구분이 되기 때문에 한 줄 단위를 꼭 지켜서 해줘야함. 보기편하기 위해 엔터를 입력하면 벌크 입력시 에러가 남
[ Bulk API]
- "create" : 인덱스를 생성하고 document 업데이트
- "index" : 해당 인덱스에 document 추가, 인덱스가 없으면 자동으로 생성하고 document가 추가된다.
- "update" : update를 하려면 body에 "doc"필드를 명시해야함
- "delete" : delete를 할 때는 body는 작성하지 않아도 됨
4. 매핑.json과 함께 인덱스 생성 시(command 버전)
curl -X PUT "localhost:9200/my-index?pretty" -H 'Content-Type: application/json' -d' @mapping.json
- 로컬에 mapping.json파일이 존재해야함.
- 미리 사용자가 지정한 대로 mapping하고 싶을 때 사용
- mapping을 정해 놓지 않으면 default로 데이터가 들어감
5. SQL문법만 알고 엘라스틱 문법이 어려울 경우 : 쉽게 변환할 수 있음
GET /_sql/translate
{
"query": "SELECT max(score) FROM gcp_failure GROUP BY c_key"
}
- 위와 같이 /_sql/translate을 사용하면, "query"에 입력한 sql 문법을 elk 문법으로 변환시킨 쿼리가 결과로 나옴
GET [인덱스이름]/_search
{
위에서 나온 결과를 그대로 사용
}
- 그 결과를 사용하여 엘라스틱 문법으로 검색을 하면, 쉽게 쿼리를 사용할 수 있음.
6. 특정 인덱스의 모든 결과 검색
GET [인덱스이름]/_search
{
"query" : {
"match_all" : {}
}
}- "query" : "match_all"을 사용하면 모든 데이터를 가져오라는 뜻. 결국 모든 document가 출력 됨.
- 위에 결과를 sorting 하고 싶을 때는 아래와 같이 사용
GET [인덱스이름]/_search
{
"query" : {
"match_all" : {}
},
"sort": [
{
"[필드명]": {
"order" : "desc" #오름차순: asc, 내림차순: desc
}
}
]
}- "sort"를 사용하면 원하는 특정 필드에 해당하는 값으로 정렬을 할 수 있음.
7. 특정 값 이상 조건 검색
GET [인덱스이름]/_search
{
"query": {
"range": {
"필드명": {
"gre": 시작 값
"gte" : 끝 값
}
}
}
}- 특정 원하는 필드에 대해 범위를 주고 조건 검색을 할 경우 사용
- 특정 값 이상으로만 검색 할 경우 "gte"는 지우고 "gre" 값만 입력 하면 됨
8. 특정 조건문에 해당하는 document만 삭제
POST [인덱스이름]/_delete_by_query?conflicts=proceed&pretty
{
"query": {
"range": {
"필드명": {
"gre": 시작 값
}
}
}
}- 위와 같이 하면 특정 필드의 값이 어떤 시작 값 이상인 문서에 해당하면 다 삭제가 된다.
- ?conflicts=proceed 를 입력하는 이유는 중간에 충돌이 나거나 타임아웃 발생시 그냥 진행 되도록 한다.
9. 기존 인덱스에 새로운 필드 추가
POST [인덱스이름]/_mapping
{
"새로 매핑할 정보 입력"
}- 새로운 field에 대한 매핑 정보를 post로 입력하면된다.
- mapping에 들어갈 정보를 입력하면, 원하는 형태의 매핑으로 들어가짐
- 아래는 예시 화면
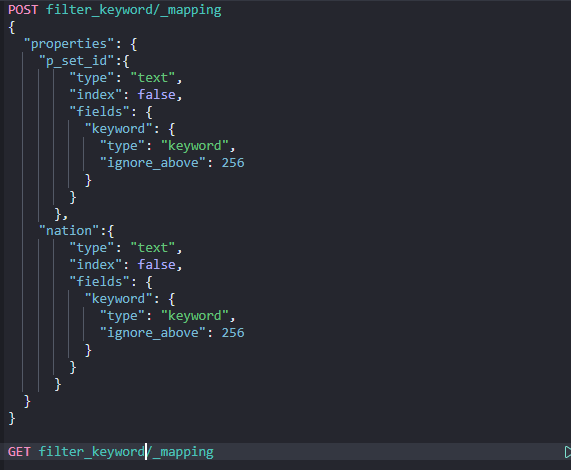
- 새롭게 추가한 field가 잘 적용되었는지 확인하기 위해 아래와 같이 입력하여 매핑정보 확인하기
GET [인덱스이름]/_mapping
10. 모든 다큐먼트의 데이터 수정(특정 필드)
- 이미 데이터를 넣어 놓은 상태에서, 모든 다큐먼트의 특정 필드의 값이 전부다 변경이 필요할 때
- 아래와 같이 활용하면 적용이 된다. 다큐먼트가 많을수록 시간이 많이 소요됨
- time out 에러를 방지하기 위해 뒤에 파라미터로 wait_for_comletion=false 붙여준다
PUT _ingest/pipline/set_change
{
"description" : "set_changing",
"processors" : [{
"set": {
"filed" : "[변경을 원하는 필드명]",
"value" : "[변경 할 데이터 값]"
}
}]
}
POST [위 변경을 적용할 인덱스이름]/_update_by_query?pipeline=set_change&wait_for_completion=false
11. 키바나에서 문법 사용 시 주의
- 키바나는 Kibana Query Language / Lucene Query Syntax 이렇게 2개의 문법이 존재 함
- 두개 문법의 사용 법이 다르기 때문에 해당하는 문법으로 검색해야 결과가 나옴
https://www.elastic.co/guide/en/kibana/7.5/kuery-query.html
Kibana Query Language | Kibana Guide [7.5] | Elastic
Terms without fields will be matched against the default field in your index settings. If a default field is not set these terms will be matched against all fields. For example, a query for response:200 will search for the value 200 in the response field,
www.elastic.co
- 키바나에서 on/off로 원하는 문법을 설정할 수 있다.
- 설정 on : Kibana Query Language, off : Lucene Query Syntax
