유사 이미지 검색 분야 관련 블로그 글을 번역
& 실제 테스트하는 내용의 포스팅입니다.
"원본 링크 [출처]
https://medium.com/@kumon/how-to-realize-similarity-search-with-elasticsearch-3dd5641b9adb"
이전 포스트에서 언급했듯이 아마존 엘라스틱 서비스의 kNN 기능이 지연시간 있었다. 아마존 ES 팀으로부터 지원을 받아, 실제 구성 및 제한이 명확 해졌다.
Introduction
이전 포스트에서, 벡터의 차원이 1280인 약 1M의 데이터를 엘라스틱에 넣었다.
그러나 각각의 쿼리 요청 당 대략 15초의 쿼리 지연시간은 실용적이지 못했다. 아마존의 ES팀은 목적에 적합한 구성을 해야 한다고 조언했다.
Elasticsearch에 익숙한 소프트웨어 엔지니어에게는 매우 간단하고 기본적인 내용일 수 있다. 상업적인 목적으로 Elasticsearch를 사용한 적이 없으므로 이 내용은 나에겐 매우 유용했다.
Segments
이전 포스트의 엘라스틱의 응답의 처음을 잘 살펴보면, hits의 수가 1203이다. 이것은 엘라스틱 인덱스에 적어도 120개의 segment가 있다는 것을 의미한다. 각각의 segments에 대해, k개의 후보 벡터가 추출되고, 그 결과 가장 유사한 k개의 벡터가 선택된다.

더 정확하게, 엘라스틱 인덱스는 샤드에 의해 나눠진다. 각각이 샤드는 Lucene 인덱스이다. 각각의 Lucene인덱스는 segments라고 불리는 여러 개의 파일로 나눠진다. segments들이 순차적으로 스캔되기 때문에, 적은 segments는 더 좋은 성능 향상을 가지고 온다.
기본 세팅은 각각의 인덱스에 대한 샤드의 수는 5이다. 그래서 전체에서 5개의 segment가 이상적인 숫자이다.
Configurations
인덱싱 성능을 향상하기 위해, 다음 세팅을 추가한다.
- index.refresh_interval = -1 (default: 1 sec)
- index.translog.flush_threshold_size = '10gb' (default: 512mb)
- index.number_of_replicas = 0 (default: 1)
참고자료
또한 인덱싱 스레드 수를 늘리는 것이 좋습니다. 다음은 관련 기사이다.
Tune for indexing speed | Elasticsearch Reference [7.7] | Elastic
Tune for indexing speededit Use bulk requestsedit Bulk requests will yield much better performance than single-document index requests. In order to know the optimal size of a bulk request, you should run a benchmark on a single node with a single shard. Fi
www.elastic.co
Amazon Elasticsearch Service에서 인덱싱 성능 개선
플러시 임계값 크기를 늘리려면 다음 API 작업을 호출합니다. 이 예제에서는 플러시 임계값 크기가 1,024 MB로 설정되어 있으며, 이는 32GB 이상의 메모리가 있는 인스턴스에 적합합니다. 사용 사례�
aws.amazon.com
opendistro-for-elasticsearch/k-NN
🆕 A machine learning plugin which supports a k-NN proximity algorithm for Open Distro for Elasticsearch - opendistro-for-elasticsearch/k-NN
github.com
Sample Code
아래 코드는 벡터를 인덱싱 하기 위해 업데이트된 코드이다.
# 필요한 라이브러리 로딩
import time
import math
import numpy as np
import json
import certifi
from elasticsearch import Elasticsearch, helpers
from sklearn.preprocessing import normalize
# 벡터 차원 선언
dim = 1280
# 저장 된 벡터 로딩
fvecs = np.memmap('fvecs.bin', dtype='float32', mode='r').view('float32').reshape(-1, dim)
# 인덱스 이름
idx_name = 'imsearch'
# 엘라스틱 접속
es = Elasticsearch(hosts=['https://vpc-xxxxxxxxxxx.us-west-2.es.amazonaws.com'],
ca_certs=certifi.where())
# cluster 세팅 추가
res = es.cluster.put_settings({'persistent': {'knn.algo_param.index_thread_qty': 2}})
print(res)
# mapping 선언
mapping = {
'settings' : {
'index' : {
'knn': True,
'knn.algo_param' : {
'ef_search' : 256,
'ef_construction' : 128,
'm' : 48
},
'refresh_interval': -1,
'translog.flush_threshold_size': '10gb',
'number_of_replicas': 0
},
},
'mappings': {
'properties': {
'fvec': {
'type': 'knn_vector',
'dimension': dim
}
}
}
}
# 인덱스 생성
res = es.indices.create(index=idx_name, body=mapping, ignore=400)
print(res)
# 배치 사이즈 / 반복 수 선언
bs = 200
nloop = math.ceil(fvecs.shape[0] / bs)
# 데이터 적재
for k in range(nloop):
rows = [{'_index': idx_name, '_id': f'{i}',
'_source': {'fvec': normalize(fvecs[i:i+1])[0].tolist()}}
for i in range(k * bs, min((k + 1) * bs, fvecs.shape[0]))]
s = time.time()
helpers.bulk(es, rows, request_timeout=30)
print(k, time.time() - s)
Merge segments
위 코드를 실행시킨 후에 segments의 수는 5가 아닌 27이다. 우리는 아래 명령어를 사용하여 segment를 합칠 수 있다.
POST /[인덱스이름]/_forcemerge?max_num_segments=1
> 위 명령어를 실행하면 시간이 걸리므로 200 응답을 받을 때까지 몇 분마다 응답을 계속 모니터링한다.
> 최종적으로 나온 세그먼트 수는 5가 된다.
Refresh
index.refresh_interval = -1에 의해 새로 고침이 비활성화되므로, 이것을 실행해야 한다.
그러면, 유사 검색을 사용할 수 있다.
POST /[인덱스이름]/_refresh
Test Result
그러나, 불행하게도, 위 업데이를 해도 응답 시간은 7sec를 넘긴다. 비록 그전의 15sec 보다는 나아졌지만, 여전히 실용적인 응답시간은 아니다.
워밍업 요청은 이전과 동일하게 도움이 되지 않았다. 보시다시피, hits 수는 50이다. 이는 각 샤드에 하나의 세그먼트만 있음을 의미한다.

Memory
🔔 현재 사용 중인 엘라스틱 클러스터의 인스턴스 타입은 r5.large로 2 CPU와 16GB 메모리를 가진다. 엘라스틱은 자신을 위해 50%의 메모리를 할당한다 (최대 32GB). 남아있는 메모리의 일부분은 유사 검색을 위해 할당된다 이 시스템을 안정적으로 돌리기 위해서는 a circuit breaker(메모리 사용을 제한하는)를 실행해야 한다.
🔔 그것은 knn.memory.circuit_breaker.limit에 의해 설정되고, default 값은 60%이다. 따라서 16GB*50%*60%인 4.8GB만 사용 가능하다.
🔔 각 벡터의 차원은 1280이며, 대략 백만 장의 데이터 벡터를 넣는 것을 시도했다. HNSW는 각 벡터를 graph로 저장하기 위해 4 * d + 8 * M Bytes를 필요로 한다. 아마존 ES팀은 실제로 필요한 양보다 1.5배 큰 메모리를 사용하기를 권장한다.
🔔 이번 테스트에서 M은 48이다. 따라서 ( 4* 1280 + 8 * 48 ) * 1.5 * 1M = 7.7GB가 이 데이터 셋을 위해 필요하다.
🔔 엘라스틱은 필요한 메모리보다 1.5 배 큰 메모리를 권장합니다. 실험에서 M은 48이므로 데이터 세트에 (4 * 1,280 + 8 * 48) * 1.5 * 1M = 7.7GB가 필요하다.
🔔 따라서 r5.xlarge(4 CPU, 32GB memory) 엘라스틱 인스턴스를 생성했다. CPU의 수가 4개이기 때문에, knn.algo_param.index_thread_qty 또한 4로 업데이트를 할 수 있다.
🔔 이전과 같은 과정으로 벡터를 넣고, 인덱스를 업데이트한 후에, 클러스터에 1,000개의 요청을 보냈다. 그러면 결론적으로 유사검색은 실용적인 시간으로 작동한다. 평균 14ms정도 걸린다.
ANN with nmslib
이전 테스트에서는 보통 ANN에 faiss를 사용하기 때문에 HNSW 벤치 마크에도 사용된다. 또한 검색 성능을 직접 비교하기 위해 nmslib를 사용했다. Elasticsearch 메모리 요구 사항을 충족시키기 위해 r5.xlarge 인스턴스가 실험의 클러스터에 사용되었다. 따라서 이 벤치 마크에도 동일한 인스턴스 유형이 사용되었습니다.
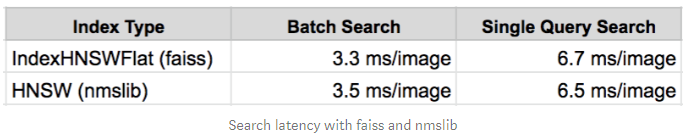
비록 nmslib을 사용한 평균 응답 시간이 기존 elasticsearch kNN보다 2배 정도 빠르지만, 이것은 합당한 비교는 아니다. 많은 경우에, 지연시간은 받아들여질 수 있다.
Conclusion
Amazon ES 팀 덕분에, 마침내 Segment 수를 줄이고 충분한 메모리를 할당하여 실용적인 응답 시간으로 유사성 검색을 실현했습니다. HNSW는 훌륭한 ANN 알고리즘입니다. 알고리즘은 원본 데이터를 유지하므로 IVFPQ (Inverted File with Product Quantization)와 같은 다른 알고리즘보다 메모리 소비가 더 높습니다. 벡터 치수가 수천 이상인 경우 이러한 벡터를 탄력 검색에 배치하기 전에 치수 축소를 고려하는 것이 좋습니다. HNSW는 백만 규모의 데이터를 위한 최고의 ANN 알고리즘 중 하나로 알려져 있습니다. 여러 서버로 구성된 elasticsearch 클러스터를 사용하면 수십 억 규모의 데이터에 대한 실질적인 ANN 검색이 가능할 수 있습니다.
'DeepLearning > Image Retrieval Search' 카테고리의 다른 글
| [번역] Similarity Search and Similar Image Search in Elasticsearch (0) | 2020.06.04 |
|---|
