처음에 작업한 training코드에서 한국어를 추가하면서 loss계산 방식을 변경.
변경 된 loss를 사용하여 다시 coco text english 데이터를 학습 시킴
< COCO-TEXT CRNN Training >
데이터 준비
- 데이터 위치 : /data/COCO_TEXT/train2014/
- 데이터 갯수 : Train 데이터 (14,708장), Validation 데이터 (3,424장)
- 데이터 출처 : coco-text
- 어노테이션 파일 존재 (이미지 속 텍스트에대한 박스 정보)
재 학습 이유
- 현재 한국어 데이터가 라벨마다 데이터 불균형이 심하기 떄문에 이를 보완하기 위해 기존 loss 계산법 변경
- 데이터 불균형에 적합한 focal_ctc_loss 사용
- 처음과 달리 학습시키는 과정에서 데이터 증식에 대한 필요성이 보여서 새롭게 추가함(training한정)
- 학습시 발생하는 잘못된 박스 모양에 대한 에러 처리
Focal CTC 관련 Paper : https://www.hindawi.com/journals/complexity/2019/9345861/
Focal CTC Loss for Chinese Optical Character Recognition on Unbalanced Datasets
In this paper, we propose a novel deep model for unbalanced distribution Character Recognition by employing focal loss based connectionist temporal classification (CTC) function. Previous works utilize Traditional CTC to compute prediction losses. However,
www.hindawi.com
COCO_TEXT Training
# 필요한 라이브러리 로딩
import numpy as np
import matplotlib.pyplot as plt
import os
import editdistance
import pickle
import time
from keras.optimizers import SGD, Adam
from keras.callbacks import ModelCheckpoint, TensorBoard
from crnn_model_focal_ctc_loss import CRNN
from crnn_data_fcl_aug_merge import InputGenerator
from crnn_utils import decode
from utils.training import Logger, ModelSnapshot- crnn_model 에서 crnn_model_focal_ctc_loss로 변경
- crnn_data 에서 crnn_data_fcl_aug_merge로 변경
# Train / Val에 대한 피클파일 로딩
with open('gt_util_cocotext_train.pkl', 'rb') as f:
gt_util_train = pickle.load(f)
with open('gt_util_cocotext_val.pkl', 'rb') as f:
gt_util_val = pickle.load(f)- 각각 피클 파일 load 하기

# 라벨이 있는 딕셔너리 로딩
from crnn_utils import alphabet87
print(len(alphabet87)) # 87- 영어에 대한 라벨 값이기 때문에 총 87개 이다.
- 소문자 / 대문자 / 숫자 / 특수기호 / blank 가 포함 된 딕셔너리
# 학습 전 필요한 변수 선언
input_width = 256
input_height = 32
batch_size = 128
input_shape = (input_width, input_height, 1)
max_string_len = 62- 최대 글자 수는 62
- 모델에 들어가는 input의 형태는 ( 256, 32, 1 )의 3차원 배열이다.
# 모델 생성하기
alpha=0.75
gamma=0.5
model, model_pred = CRNN(input_shape, len(alphabet87), gru=False, alpha=alpha, gamma=gamma)
model.load_weights('checkpoints/201806162129_crnn_lstm_synthtext/weights.300000.h5')
max_string_len = 62- 그 동안의 학습에서 alpha=0.75, gamma = 0.5가 최대 성능을 보였음
- 모델에 들어가는 가중치는 깃에 올라와 있다. (https://github.com/mvoelk/ssd_detectors)
- 위에서 사용한 가중치는 synthtext로 학습 된 가중치이다
# Transfer Learning ( 전이 학습 )
freeze = ['conv1_1',
'conv2_1',
'conv3_1', 'conv3_2',
'conv4_1',
'conv5_1',
#'conv6_1',
#'lstm1',
#'lstm2'
]
- 위에서 생성한 모델에 미리 학습 된 가중치를 load하고, 여기서 freeze를 걸어준다.
- 모델의 convnet층은 가중치를 동결시키고, 모델의 마지막 부분인 conv6_1, LSTM은 동결을 해제하여 학습될 수 있도록 한다.
- 이렇게 하는 이유는, 기존에 학습 된 가중치는 synthtext에 맞춰져 있는 데, synthtext를 확인해본 결과 데부분이 그래픽이미지에 대한 텍스트이다. 우리는 real world text에 대한 학습이 필요
- 따라서 미리 학습 된 가중치를 모델에 올리고 전이학습 진행
# 데이터 제너레이터 생성
gen_train = InputGenerator(gt_util_train, batch_size, alphabet87, input_shape[:2],
grayscale=True, max_string_len=max_string_len)
gen_val = InputGenerator(gt_util_val, batch_size, alphabet87, input_shape[:2],
grayscale=True, max_string_len=max_string_len)- Train과 Val데이터 각각 제너레이터를 만든다.
# 모델 컴파일
optimizer = Adam(lr=0.001, epsilon=0.001,decay=1e-5, clipnorm=1.)
for layer in model.layers:
layer.trainable = not layer.name in freeze
model.compile(loss={'focal_ctc_loss': lambda y_true, y_pred: y_pred}, optimizer=optimizer)
- 옵티마이져는 Adam을 사용
- 아까 설정한 레이어를 제외하고는 레이어 동결을 해제한다.
- 모델을 컴파일한다. 로스는 모델안의 lambda에서 계산된다.
# 모델 학습
hist = model.fit_generator( generator=gen_train.generate(),
steps_per_epoch=gt_util_train.num_objects // batch_size,
epochs=300,
validation_data=gen_val.generate(), # batch_size here?
validation_steps=gt_util_val.num_objects // batch_size,
callbacks=[
ModelCheckpoint(checkdir+'/weights.{epoch:03d}.h5', verbose=1, save_weights_only=True),
Logger(checkdir),
PlotLossesCallback(),
EarlyStopping(monitor='val_loss', mode='auto', restore_best_weights=True, verbose=1, patience=20)
],
initial_epoch=0)- 모델을 학습시킨다.
- epochs = 300
- 한 에폭당 가중치를 저장한다.
- 학습을 실시간으로 볼수있게 PlotLossesCallback()을 사용한다.
- 실시간으로 loss와 val_loss에 대해 그래프로 확인가능하다
- 현재 20회 동안 val_loss가 향샹되지 않으면 early stopping이 되도록 해서, 54 epoch때 학습이 멈췄다.
# 학습이 완료 된 후 로스값 그래프로 확인하기
loss = hist.history['loss']
val_loss = hist.history['val_loss']
epochs = range(len(loss))
plt.figure(figsize=(15,10))
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'b',label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()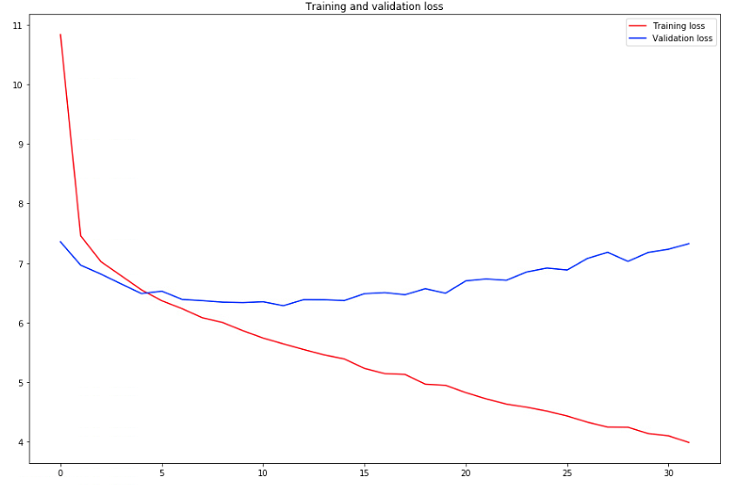
# 예측 결과 시각화
d = next(g)
res = model_pred.predict(d[0]['image_input'])
mean_ed = 0
mean_ed_norm = 0
plot_name = 'crnn_cocotext'
for i in range(32):
chars = [alphabet87[c] for c in np.argmax(res[i], axis=1)]
gt_str = d[0]['source_str'][i]
res_str = decode(chars)
ed = editdistance.eval(gt_str, res_str)
ed_norm = ed / len(gt_str)
mean_ed += ed
mean_ed_norm += ed_norm
img = d[0]['image_input'][i][:,:,0].T
plt.figure(figsize=[10,1.03])
plt.imshow(img, cmap='gray', interpolation=None)
ax = plt.gca()
plt.text(0, 45, '%s' % (''.join(chars)) )
plt.text(0, 60, 'GT: %-24s RT: %-24s %0.2f' % (gt_str, res_str, ed_norm))
plt.show()
mean_ed /= len(res)
mean_ed_norm /= len(res)
print('\nmean editdistance: %0.3f\nmean normalized editdistance: %0.3f' % (mean_ed, mean_ed_norm))- 선명한 텍스트에 대해서는 어느정도 학습이 잘되어있으나, 선명하지않은 이미지에 대해서는 잘 예측하지 못함
- 대소문자에 대한 학습이 덜 되어있다.
< OUTPUT >

하이퍼 파라미터 튜닝
Eng_CRNN_v1
1. Focal-CTC-Loss ( alpha : 0.75, gamma : 0.5)
2. act : LeakyReLU ( 0.05 )
3. lstm-dropout : 0.1, 0.1
4. data augmentation : blur / sharpenning
5. optimizer : Adam(lr=0.001, epsilon=0.001,decay=1e-5, clipnorm=1.)
6. freeze : con1_1, conv2_1, conv3_1, conv3_2, conv4_1, conv5_1
7. batch_size = 128
< Version 1 >
최소 validation loss : 2.077
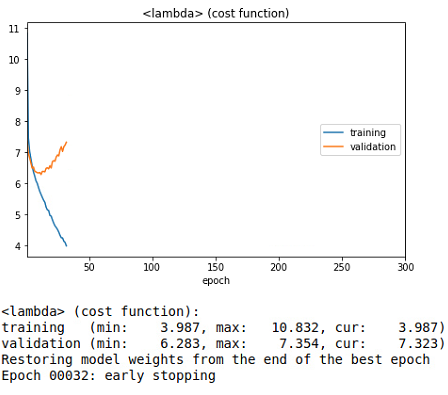
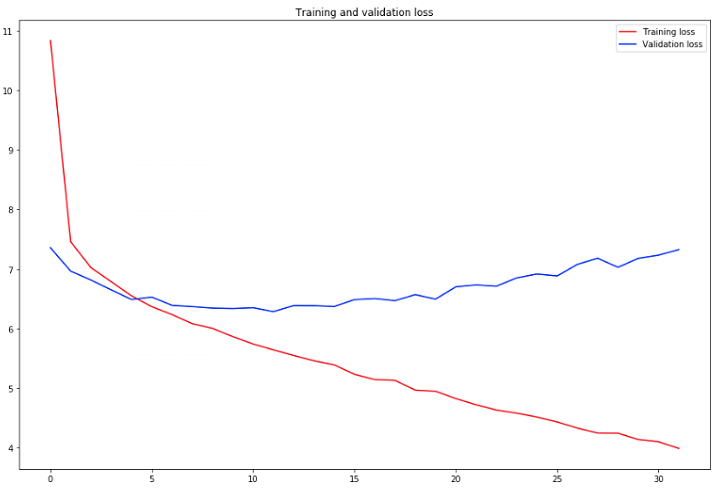
- 첫번째 그래프는 실시간으로 확인되는 그래프
- 에폭을 300번 주었으나 early stopping으로 32epoch에서 멈췄다.
- 두번째 그래프는 loss와 val_loss를 좀 더 자세하게 확인한 그래프
Eng_CRNN_v2
1. Focal-CTC-Loss ( alpha : 0.75, gamma : 0.5)
2. act : LeakyReLU ( 0.05 )
3. lstm-dropout : 0.1, 0.1
4. data augmentation : blur / sharpenning
5. optimizer : Adam(lr=0.0001, epsilon=0.001,decay=1e-5, clipnorm=1.)
6. freeze : con1_1, conv2_1, conv3_1, conv3_2, conv4_1, conv5_1
7. batch_size = 64
- 변경사항 : 배치사이즈를 128 > 64로 낮춤, learning rate을 0.001 > 0.0001로 낮춤
< Version 1 >
최소 validation loss : 2.077
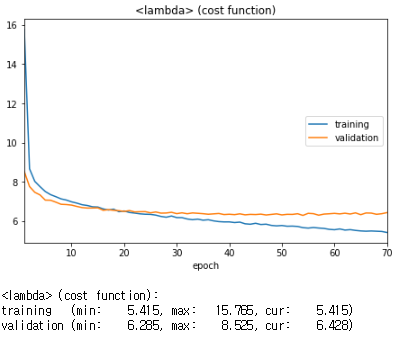
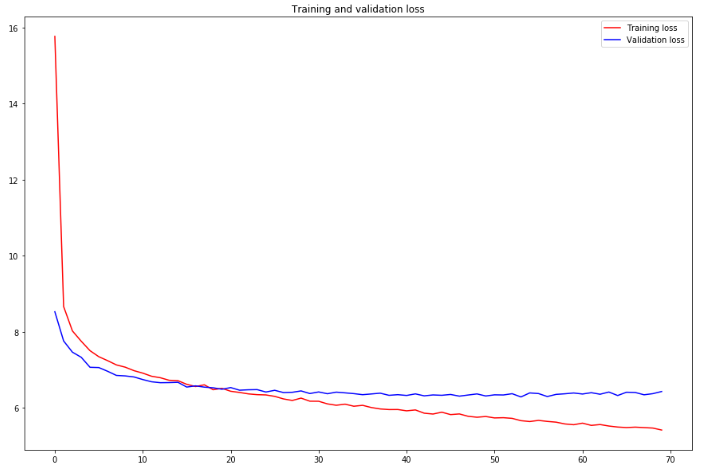
- 배치사이즈를 줄이고, learning rate를 줄였더니 어느정도 이해가 되는 그래프로 그려짐
- 그러나 최종 val_loss값에는 큰 차이가 없음
- dropout층이 있어서 학습 초반에는 training loss가 더 높다. 시간이 지나면서 val_loss가 더 높아짐
Eng_CRNN_v3
1. Focal-CTC-Loss ( alpha : 0.25, gamma : 1)
2. act : LeakyReLU ( 0.05 )
3. lstm-dropout : 0.1, 0.1
4. data augmentation : blur / sharpenning
5. optimizer : Adam(lr=0.0001, epsilon=0.001,decay=1e-5, clipnorm=1.)
6. freeze : con1_1, conv2_1, conv3_1, conv3_2, conv4_1, conv5_1
7. batch_size = 64
- 변경사항 : Focal-CTC-Loss의 alpha값이 0.75 > 0.25, gamma 값이 0.5 > 1로 변경
- 한국어가 라벨의 불균형이 심해 Focal-CTC-Loss를 적용시켰으나, 상대적으로 영어는 라벨이 불균형이 심하지 않기 때문에 다른 alpha와 gamma값을 다르게 적용해야한다고 생각이 들어 값을 변경함
- data augmentation은 Train data에만 적용
< Version 1 >
최소 validation loss : 2.077
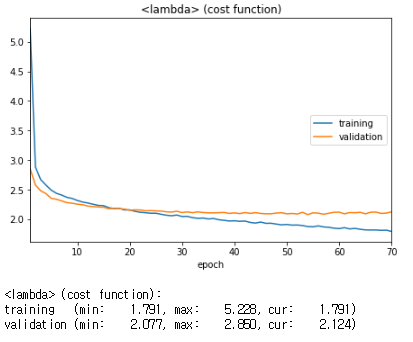
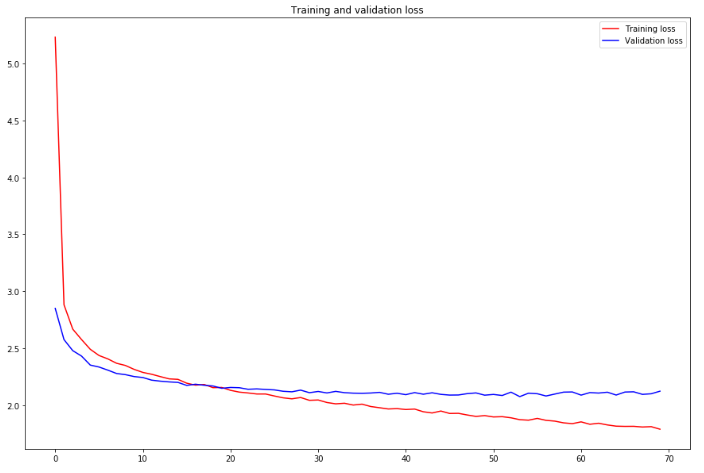
- 알파와 베타 값을 변경하고 시작하는 loss값부터 굉장히 많이 떨어진 것을 볼 수 있다.
- 확실한 성능의 향상이 보임
# coco-text의 문제점 발견 : text labeling이 대소문자가 잘못 되어 있는 경우가 생각 보다 많이 보임

- 현재 위의 사진을 보면 GT가 텍스트 라벨링 값, RT가 모델을 사용한 예측 값
- 통일되지 않게 라벨링 되어있는 것을 확인 할 수 있음
'DeepLearning > OCR_' 카테고리의 다른 글
| [KR_OCR] 최종 Training (0) | 2019.05.22 |
|---|---|
| [OCR] CRNN_Model에 사용한 다른 util.py (0) | 2019.05.09 |
| [KR_OCR] Training(하이퍼파라미터튜닝)_v2 (0) | 2019.05.04 |
| [KR_OCR] Training(하이퍼파라미터튜닝)_v1 (0) | 2019.04.26 |
| [KR_OCR] 데이터수집을 위한 어노테이션 (3) | 2019.04.22 |



