앞으로 진행 할 CRNN 관련 포스팅에서
사용되는 논문과 코드에 대해 적어둔 포스팅입니다:)
1. 참고 논문 (Text Recognition)
Reference Paper : https://arxiv.org/abs/1507.05717
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A
arxiv.org
>> CRNN에 BASE가 되는 논문 자료
>> 논문에서 사용 된 모델 구조
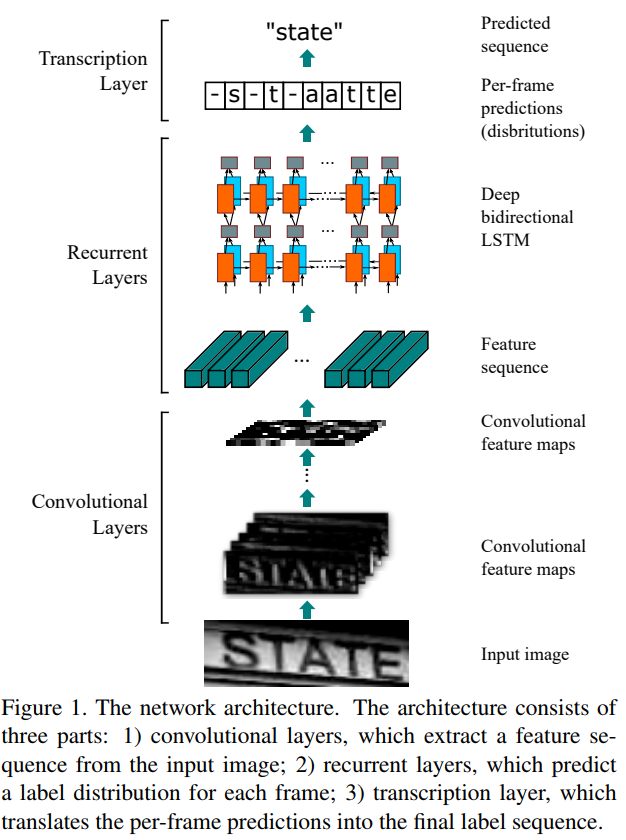
논문에 언급되어있는 CRNN에 사용 할 모델 구조 : Convolutional Layers + Recurrent Layers + Transcription Layers
- Convolutional Layer : 입력 이미지로부터 특징 시퀀스를 추출.
- Recurrent Layers : 각 프레임마다 라벨을 예측.
- Transcription Layers : 프레임마다의 예측을 최종 라벨 시퀀스로 변경.
2. 참고 깃 허브 (Text Recognition)
Refernce Github : https://github.com/mvoelk/ssd_detectors
mvoelk/ssd_detectors
SSD-based object and text detection with Keras, SSD, DSOD, TextBoxes, SegLink, TextBoxes++, CRNN - mvoelk/ssd_detectors
github.com
>> 이번에 CRNN구현에 있어 BASE로 사용한 깃허브 코드
>> CRNN_train.ipynb, crnn_data.py, crnn_model.py, crnn_utils.py, crnn_cocotext.py 참고
3. 최종 코드 (Text Recognition)
>> 위의 2가지의 베이스 자료를 통해 수정 작업
##DONE
- COCO의 2014 Train, 2014 Val datasets을 사용하기 위해 pickle파일을 2개 생성
- CRNN train 도중 발생되는 오류 해결
##TODO
- Data Augmentation을 사용하기 위한 Generator 코드 수정
- 한국어 OCR을 위한 기본 Architecture 수정
4. 사용한 데이터 셋 (Text Recognition)
Datasets : http://cocodataset.org/#home
COCO - Common Objects in Context
cocodataset.org
>> COCO에서 제공하는 2014Train / 2014Val data를 활용하여 학습
>> COCO-Text에서 제공하는 COCO-Text annotation을 사용
COCO-Text data set은 용량이 크기 때문에 gsutil을 사용하여 다운로드 받는 것을 추천
- Install gsutil via : curl https://sdk.cloud.google.com | bash
- Make local dir : mkdir train2014
- Synchronize via : gsutil -m rsync gs://images.cocodataset.org/train2014 train2014
- Annotation : coco-text에서 다운받을 수 있다 (파일명은 COCO-Text.json)
# 위의 순서는 리눅스에서 사용하기때문에, 윈도우를 사용하는 경우에는 Google Cloud Platfrom을 설치 하고 gsutil 명령어를 사용해야 데이터를 다운 받을 수 있다.
# 이미지파일은 12G정도 되기때문에 다운받는데 시간이 꽤 소요되고, 어노테이션은 금방 다운받을 수 있다.
'DeepLearning > OCR_' 카테고리의 다른 글
| [KR_OCR] 한국어 데이터셋(AI HUB) (0) | 2019.04.09 |
|---|---|
| [ENG_OCR] ImageWithTextBoxes 디버깅을 위한 코드 (0) | 2019.04.08 |
| [ENG_OCR] CRNN_Training 모델 학습 프로세스 (0) | 2019.04.08 |
| [ENG_OCR] CRNN_cocotext 데이터 전처리 작업 (0) | 2019.04.06 |
| [OCR] CRNN Model_기본 구조 (2) | 2019.04.04 |


