셀레니움, Ajax를 활용한 네이버 플레이스 정보 크롤링
학습용으로 만든 자료.
Introduction
기본 url을 네이버 맵으로 주고, 다양한 검색어를 검색하여 상세보기로 들어간 뒤, 해당하는 플레이스의 정보와, 예약자 리뷰, 블로그 리뷰를 가져오는 코드.
Install_Library
# 셀레니움 설치
pip install selenium- 라이브러리를 사용하려면 해당 라이브러리의 설치가 먼저 선행되어야함
# 크롬 드라이버 설치
https://sites.google.com/a/chromium.org/chromedriver/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
sites.google.com
- 크롬 드라이버를 설치하기 위해 위의 링크를 참고
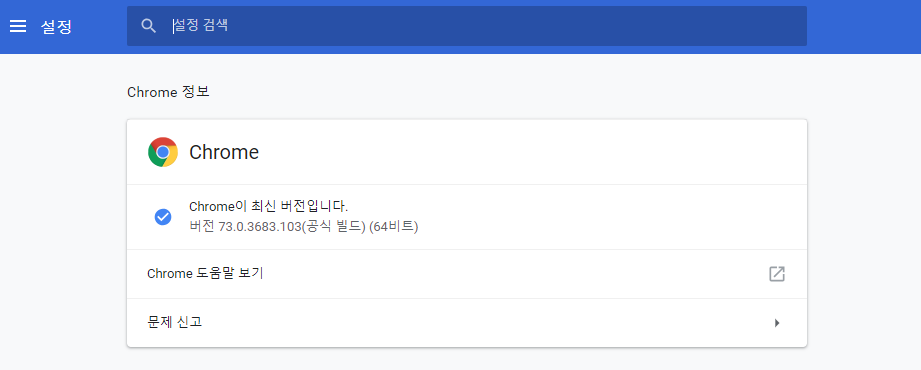
- 현재 크롬의 버전을 확인 후 해당 버전에 받는 ChromeDriver 설치
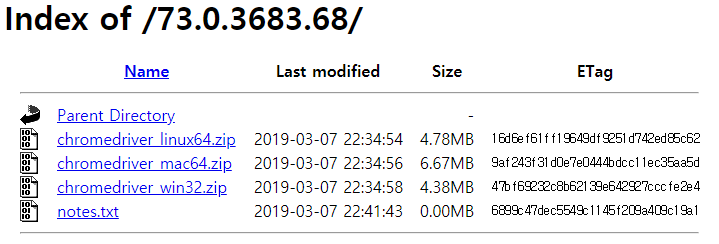
- 현재 사용하는 크롬이 73버전이므로, 해당 버전에 본인의 pc에 해당하는 os의 zip을 설치
- 다운받은 후 압축을 풀고 현재 작업하는 경로에 chromedriver.exe를 옮긴다
Loading Library
from bs4 import BeautifulSoup
import requests
from urllib.request import urlopen
import json
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import ElementNotVisibleException- 필요한 라이브러리를 먼저 로딩한다
Selenium_Webdriver
# 웹 드라이버 로딩
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)- driver가 로딩 될 때까지 기다리기 위해 implicitly_wait(3)을 준다
# 검색 쿼리로 보낼 json파일을 로딩
with open('file.json','r', encoding='utf-8-sig') as f:
data = json.load(f)
data = data['hits']
- 한글로 작성 된 json파일을 읽을 때는 encoding = 'utf-8-sig'을 주어야 한글깨짐 현상 없이 읽을 수 있음
<참고사항>
# 여기서 사용 된 file.json은 공공 데이터 포탈에 있는 음식점 현황 자료를 사용 함
# file.json안에 상호명과 도로명 주소를 파싱하여 검색어 쿼리로 사용하기 위함
# 파일이 없을 경우 아래 query에 직접 음식점 명을 입력 ex ) query = "상호명" or query = ["상호명1","상호명2"]
# 셀레니움으로 네이버 맵을 열고, 쿼리로 검색어를 보냄.
naver_url = "https://map.naver.com/"
driver.get(naver_url)
# 쿼리로 검색할 상호명과 도로명 주소를 함께 검색
# i는 변수
query = data['hits'][i]['_source']['상호명']+" " + data['hits'][i]['_source']['도로명주소'].split(' ')[2]- 검색쿼리 갯수만큼 반복문을 돌린다.
- 같은 상호명이 많기 때문에 도로명 주소를 함께 검색한다
# 네이버 맵에서 개발자 모드 함께 켜놓고 원하는 부분의 태그 확인
driver.find_element_by_xpath('//*[@id="search-input"]').clear()
driver.find_element_by_xpath('//*[@id="search-input"]').send_keys(query)
driver.find_element_by_xpath('//*[@id="header"]/div[1]/fieldset/button').click()- driver.find_element_by_xpath : x_path를 주면 그 위치를 찾는다.
- clear() : 선택 된 곳을 빈값으로
- send_keys() : 쿼리를 입력
- click() : 버튼을 클릭

<빨간색 박스>
- 우선 검색어를 쿼리로 보내기 위해 검색창을 clear()를 시킨다
- 검색창의 x_path를 찾고 그 곳에 쿼리를 키값으로 보낸다.
<파란색 박스>
- 키를 보낸 뒤 검색버튼을 클릭하게 한다.
Naver Map_Detail
#Try Error 구문
try:
click = driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl")
if store_name in click.text:
click.click()
else:
print("--해당음식점이 없습니다")
continue
try:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except ElementNotVisibleException:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl").click()
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except NoSuchElementException:
print('--검색결과가 없습니다')
query2 = data2['hits'][i]['_source']['상호명']+" " + data2['hits'][i]['_source']['도로명주소'].split(' ')[1]
driver.find_element_by_xpath('//*[@id="search-input"]').clear()
driver.find_element_by_xpath('//*[@id="search-input"]').send_keys(query2)
driver.find_element_by_xpath('//*[@id="header"]/div[1]/fieldset/button').click()
try:
click = driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl")
if store_name in click.text:
click.click()
else:
print("--해당음식점이 없습니다")
continue
try:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except ElementNotVisibleException:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl").click()
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except NoSuchElementException:
print('--검색결과가 없습니다')
continue- 태그 클릭 시 발생되는 다양한 오류들이 존재
- 발생되는 오류들은 미리 라이브러리를 import시킨다.
- try error 구문을 통해 error가 발생하면 반복문이 종료 되도록 continue를 설정한다.
- 가장 빈번하게 발생하는 오류는 다음과 같다
1. ElementNotVisibleException
2. NoSuchElementException
- 위의 코드가 실행되면 검색어에 해당하는 네이버 플레이스창이 새롭게 열린다
Naver Place_Detail
# 새롭게 열린 창을 활성 창으로 변경
driver.switch_to.window(driver.window_handles[-1])
- 활성탭을 변경안하면 그 전에 실행중인 창을 현재 활성 창으로 인식한다
# 현재 url
url = driver.current_url
ter = url.index("=")
place_a_id = (url[ter:])[1:]- driver의 현재 url을 가져온다(새롭게 변경된 활성 창)
if "#" in place_a_id:
place_a_id = place_a_id.split('#')[0]- url 속에 앞으로 사용해야할 place_id가 있기 때문에 그 부분을 따로 추출한다
# param으로 보내는 id의 html
params = {
"id":place_a_id
}
print(place_a_id)
naver_place_url = "https://store.naver.com/restaurants/detail?"
response_url = requests.get(naver_place_url,params=params).url
try:
page = urlopen(response_url)
except HTTPError:
print('HTTPError')
driver.close()
driver.switch_to.window(driver.window_handles[0])
continue- 가져온 id를 param으로 보내준다
- 기본 베이스 url을 설정하고, get방식으로 가져온다(이때 params로 params를 보낸다)
- 잘못 된 id가 들어오는 경우가 있기 때문에 error처리도 함께 해준다.
# html.parser를 통해 읽기
soup = BeautifulSoup(page,"html.parser")- BeautifulSoup 라이브러리를 통해 보기 좋게 html을 읽는다.
# 원하는 정보 추출
place_info = soup.select_one("#content > div:nth-of-type(2) > div.bizinfo_area > div")
place_info_attrs = place_info.find_all("div", attrs={"class":"list_item"})
dict_store_one['상호명'] = data2['hits'][i]['_source']['상호명']
for i in range(len(place_info_attrs)):
key = place_info_attrs[i].span['aria-label']
value = place_info_attrs[i].text
dict_store_one[key] = value
- 원하는 정보를 감싸고 있는 태그를 찾아 정보를 가져온다
- select_one() : 해당하는 정보 하나 찾기
- find_all() : 해당하는 정보를 리스트로 찾기
- 정보를 담을 dictionary에 key와 value로 담아준다
# 추가적인 정보를 얻기 위해 info 읽기
info = soup.select_one('#content > div:nth-child(1) > div.biz_name_area > div > div').text- info를 통해 예약자 리뷰와 블로그 리뷰가 있는지 없는지 확인 할 수 있다.
Naver Review_blog
# info에 블로그 리뷰가 있는지 확인(없을 경우)
if not '블로그 리뷰' in info:
print('--블로그 리뷰 : 0')
dict_store_one['__블로그리뷰__']=[]- 블로그 리뷰가 없으면, dictionary에 빈 리스트를 넣는다.
# info에 블로그 리뷰가 있는지 확인(있을 경우)
elif '블로그 리뷰' in info:
headers2={
"Referer":"https://store.naver.com/restaurants/detail?",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
params2 = {
"exclude":"",
"businessId":place_a_id,
"category":"restaurant",
"start": 1,
"display": 50
}
naver_blog_url = "https://store.naver.com/sogum/api/fsasReviews"
res = requests.get(naver_blog_url,headers=headers2, params=params2)
blog_dict = json.loads(res.text)
print('--블로그 리뷰 : ',len(blog_dict['items']))- 블로그 리뷰가 있을 경우 파라미터로 id를 넘겨준다
- 그리고 해당 플레이스의 블로그 리뷰의 url이 담겨져있는 ajax를 가져온다(get방식)
- ajax을 읽은 뒤 사용하기 좋게 dict형태로 바꿔준다
# 블로그 리뷰의 url이 담긴 리스트생성
all_blog_text = []
for i in range(len(blog_dict['items'])):
url = blog_dict['items'][i]['url']
page = urlopen(url)
soup_1 = BeautifulSoup(page,"html.parser")
blog_text = []
if len(soup_1.find_all(attrs={"class":"se_textarea"})) != 0:
for t in soup_1.find_all(attrs={"class":"se_textarea"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"class":"se-module se-module-text"})) != 0:
for t in soup_1.find_all(attrs={"class":"se-module se-module-text"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"align":"center"})) != 0:
for t in soup_1.find_all(attrs={"align":"center"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"class":"post_ct"})) != 0:
for t in soup_1.find_all(attrs={"class":"post_ct"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
else:
print('새로운 형식의 블로그')
print(url)
all_blog_text.append(blog_text)
dict_store_one['__블로그리뷰__'] = all_blog_text- 블로그 리뷰의 갯수만큼 반복문을 돌린다
- 최대 50개 까지만 가져오도록 설정
- 해당 url을 하나씩 열어서 html을 가져온다
- 블로그마다 다양한 방식으로 포스팅을 했기 때문에 태그도 다 다르다
- 조건문을 통해 조건에 맞는 태그가 있므면 그 안의 텍스트를 가져와서 리스트에 담는다
Naver Review_booking
# info에 예약자 리뷰가 있는지 확인(없을 경우)
if not '예약자 리뷰 ' in info:
print('--예약자 리뷰 : 0')
dict_store_one['__예약자리뷰__'] = []- 예약자 리뷰가 없으면, dictionary에 빈 리스트를 넣는다
# info에 예약자 리뷰가 있는지 확인(없을 경우)
elif '예약자 리뷰 ' in info:
booking_review = []
soup_2= soup.select_one('#content > div:nth-child(1) > div.func_btn_area > ul > li:nth-child(1) > a')
bookingBusinessId = soup_2['href'].split('/')[-1].split('?')[0]
for i in range(10):
headers3 = {
"Referer": "https://store.naver.com/restaurants/detail",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
params3 = {
"bookingBusinessId":bookingBusinessId,
"page" : i,
"display" : 10,
"businessType": "restaurant"
}
reviewurl = "https://store.naver.com/sogum/api/bookingReviews"
res2 = requests.get(reviewurl, headers=headers3, params = params3)
txt_dict = json.loads(res2.text)
if len(txt_dict['items']) == 0:break
for txt in range(len(txt_dict['items'])):
review = txt_dict['items'][txt]['reviewBody']
booking_review.append(review)
print('--예약자 리뷰 : ',len(booking_review))
dict_store_one['__예약자리뷰__'] = booking_review- ajax로 한번에 리뷰를 가져오기 위해 bookingbusinessid를 찾는다
- 예약자 리뷰는 최대 100개로 지정하고 반복문을 돌린다(display 최대 10개)
- header와 params을 정의한다.
- 가져올 ajax를 get방식으로 가져온뒤 dict 타입으로 로딩시킨다.
- 가져온 ajax에서 필요한 부분인 'reviewBody'만 가져와서 리스트에 담는다.
ChromeDriver_Close
# 드라이버를 닫고 활성탭 변경
driver.close()
driver.switch_to.window(driver.window_handles[0])- 하나의 query가 다돌고 나면 다시 네이버 맵 창에서 작업을 실행
- 다시 네이버 맵의 창이 활성 창으로 설정되면 검색어 쿼리를 다시 줄 수 있다
- 그래서 상단의 코드에서 clear() 시킨것 : 그 전 검색어를 지우기 위해
Save_JsonFile
# 딕셔너리 파일 구성하기
dict_store = {}
dict_store[query] = dict_store_one- 현재 dict_store_one에 다양한 key와 value로 저장되어있는 상태
- 모든 플레이스를 한곳에 담기 위해 key = query로 주고, dict_store_one이 value로 담기는 딕셔너리 생성
- 모든 가게 정보가 담긴 딕셔너리가 dict_store 이다
# idx가 20개 될 때마다 저장
if idx % 20 == 0:
with open('naverPlaceDataSet.json', 'a', encoding='UTF-8-sig') as file:
file.write(json.dumps(dict_store, ensure_ascii=False))
dict_store = {}
print('****************저장완료****************') - idx가 1씩 증가하도록 로직을 구성하고, 20의 배수가 될 때 마다 덮어쓰기로 저장
- 파일을 저장 할 때 'ensure_ascii=False' 로 주어야 한글 깨짐현상이 안일어난다
- idx가 20이 될 때마다 저장을 하는데, 저장한 후에는 딕셔너리를 리셋해준다
여기서 중요한 점! 파일을 덮어쓰기가 아닌 이어쓰기를 하려면 'a'를 설정 값으로 주어야함!!!
Load saveFile
with open('test.json', 'r', encoding='utf-8-sig') as f:
text_data = f.read()
text_data2 = '[' + re.sub(r'\}\}\{', '}}, {', text_data) + ']'
json_data = json.loads(text_data2) - 'a' 형식으로 저장하게 되면, 새로운 형태로 저장이 된다 (ex) 딕셔너리안에 딕셔너리
- json.loads는 리스트안의 딕셔너리 형태일 경우에 사용이 가능하다
- 그래서 'a'로 저장된 파일을 읽으려면, 데이터를 감싸고 있는 { 딕셔너리 }를 [ 리스트 ] 로 변경해주어야한다
- 일단 파일을 .read()로 읽고, 리스트로 형변환해준뒤, json.loads()로 파일을 읽는다
Final_code_PYTHON
naverPlace.py
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome('./chromedriver', chrome_options = options)
driver.implicitly_wait(3)
with open('file.json','r', encoding='utf-8-sig') as f:
data = json.load(f)
data2 = data['hits']
dict_store = {}
naver_url = "https://map.naver.com/"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
driver.get(naver_url)
idx = 750
for i in range(751,len(data2['hits'])):
idx += 1
print('idx =',idx)
print(i, "=============>>", data2['hits'][i]['_source']['상호명'])
dict_store_one = {}
query = data2['hits'][i]['_source']['상호명']+" " + data2['hits'][i]['_source']['도로명주소'].split(' ')[2]
store_name = data2['hits'][i]['_source']['상호명']
if '단란주점' in store_name:
continue
driver.find_element_by_xpath('//*[@id="search-input"]').clear()
driver.find_element_by_xpath('//*[@id="search-input"]').send_keys(query)
driver.find_element_by_xpath('//*[@id="header"]/div[1]/fieldset/button').click()
try:
click = driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl")
driver.implicitly_wait(10)
if store_name in click.text:
click.click()
else:
print("--해당음식점이 없습니다")
continue
try:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except ElementNotVisibleException:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl").click()
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except NoSuchElementException or WebDriverException:
print('--검색결과가 없습니다')
query2 = data2['hits'][i]['_source']['상호명']+" " + data2['hits'][i]['_source']['도로명주소'].split(' ')[1]
driver.find_element_by_xpath('//*[@id="search-input"]').clear()
driver.find_element_by_xpath('//*[@id="search-input"]').send_keys(query2)
driver.find_element_by_xpath('//*[@id="header"]/div[1]/fieldset/button').click()
try:
click = driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl")
if store_name in click.text:
click.click()
else:
print("--해당음식점이 없습니다")
continue
try:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except ElementNotVisibleException:
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[1]/dl").click()
driver.find_element_by_xpath("//*[@id='panel']/div[2]/div[1]/div[2]/div[2]/ul/li[1]/div[2]/ul/li[4]/a").click()
except NoSuchElementException:
print('--검색결과가 없습니다')
continue
driver.switch_to.window(driver.window_handles[-1])
url = driver.current_url
ter = url.index("=")
place_a_id = (url[ter:])[1:]
if "#" in place_a_id:
place_a_id = place_a_id.split('#')[0]
params = {
"id":place_a_id
}
print(place_a_id)
naver_place_url = "https://store.naver.com/restaurants/detail?"
response_url = requests.get(naver_place_url,params=params).url
try:
page = urlopen(response_url)
except HTTPError:
print('HTTPError')
driver.close()
driver.switch_to.window(driver.window_handles[0])
continue
soup = BeautifulSoup(page,"html.parser")
place_info = soup.select_one("#content > div:nth-of-type(2) > div.bizinfo_area > div")
place_info_attrs = place_info.find_all("div", attrs={"class":"list_item"})
dict_store_one['상호명'] = data2['hits'][i]['_source']['상호명']
for i in range(len(place_info_attrs)):
key = place_info_attrs[i].span['aria-label']
value = place_info_attrs[i].text
dict_store_one[key] = value
info = soup.select_one('#content > div:nth-child(1) > div.biz_name_area > div > div').text
if not '블로그 리뷰' in info:
print('--블로그 리뷰 : 0')
dict_store_one['__블로그리뷰__']=[]
elif '블로그 리뷰' in info:
headers2={
"Referer":"https://store.naver.com/restaurants/detail?",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
params2 = {
"exclude":"",
"businessId":place_a_id,
"category":"restaurant",
"start": 1,
"display": 50
}
naver_blog_url = "https://store.naver.com/sogum/api/fsasReviews"
res = requests.get(naver_blog_url,headers=headers2, params=params2)
blog_dict = json.loads(res.text)
print('--블로그 리뷰 : ',len(blog_dict['items']))
all_blog_text = []
for i in range(len(blog_dict['items'])):
url = blog_dict['items'][i]['url']
page = urlopen(url)
soup_1 = BeautifulSoup(page,"html.parser")
blog_text = []
if len(soup_1.find_all(attrs={"class":"se_textarea"})) != 0:
for t in soup_1.find_all(attrs={"class":"se_textarea"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"class":"se-module se-module-text"})) != 0:
for t in soup_1.find_all(attrs={"class":"se-module se-module-text"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"align":"center"})) != 0:
for t in soup_1.find_all(attrs={"align":"center"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
elif len(soup_1.find_all(attrs={"class":"post_ct"})) != 0:
for t in soup_1.find_all(attrs={"class":"post_ct"}):
txt = t.get_text()
if len(txt) == 0:
continue
blog_text.append(txt)
else:
print('새로운 형식의 블로그')
print(url)
all_blog_text.append(blog_text)
dict_store_one['__블로그리뷰__'] = all_blog_text
if not '예약자 리뷰 ' in info:
print('--예약자 리뷰 : 0')
dict_store_one['__예약자리뷰__'] = []
elif '예약자 리뷰 ' in info:
booking_review = []
soup_2= soup.select_one('#content > div:nth-child(1) > div.func_btn_area > ul > li:nth-child(1) > a')
bookingBusinessId = soup_2['href'].split('/')[-1].split('?')[0]
for i in range(10):
headers3 = {
"Referer": "https://store.naver.com/restaurants/detail",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
params3 = {
"bookingBusinessId":bookingBusinessId,
"page" : i,
"display" : 10,
"businessType": "restaurant"
}
reviewurl = "https://store.naver.com/sogum/api/bookingReviews"
res2 = requests.get(reviewurl, headers=headers3, params = params3)
txt_dict = json.loads(res2.text)
if len(txt_dict['items']) == 0:break
for txt in range(len(txt_dict['items'])):
review = txt_dict['items'][txt]['reviewBody']
booking_review.append(review)
print('--예약자 리뷰 : ',len(booking_review))
dict_store_one['__예약자리뷰__'] = booking_review
dict_store[query] = dict_store_one
driver.close()
driver.switch_to.window(driver.window_handles[0])
print()
if idx % 10 == 0:
with open('./jsonsave/text.json', 'a', encoding='UTF-8-sig') as file:
file.write(json.dumps(dict_store, ensure_ascii=False))
dict_store = {}
print('****************저장완료****************')
driver.close()'Tutorial' 카테고리의 다른 글
| [AMAZON] EC2 프리티어로 API서버 구축 + Elaticsearch + Kafka (2) | 2020.01.22 |
|---|---|
| [AMAZON] EC2 프리티어 사용 / 인스턴스 생성 (0) | 2020.01.21 |
| [Pycharm] 설치 및 서버연결(gpu설정) (0) | 2019.09.08 |
| [TF serving] 딥러닝 모델 Tf serving에 올리기 (0) | 2019.05.08 |
| [다나와리뷰] 크롤링하기(ajax 활용) (5) | 2019.04.21 |



