아래 자연어처리는 네이버 플레이스에서 크롤링한
네이버 예약자리뷰 데이터를 사용하여 진행
Gensim : Python Library
토픽 모델링 라이브러리
- 아래의 홈페이지에 들어가면 튜토리얼과 설치에 대한 내용을 확인 할 수 있으며 자연어처리에 주로 사용.
https://radimrehurek.com/gensim/
gensim: topic modelling for humans
Efficient topic modelling in Python
radimrehurek.com
TextRank Summariser
- summarization.summarizer : 이 모듈은 텍스트를 요약하는 기능을 제공하며 TextRank 알고리즘의 변형을 사용하여 텍스트 문장의 순위에 기반한 요약
- 여기서 말하는 TextRank 알고리즘은 아래의 논문을 이야기한다.
Federico Barrios, Federico L´opez, Luis Argerich, Rosita Wachenchauzer (2016). Variations of the Similarity Function of TextRank for Automated Summarization : https://arxiv.org/abs/1602.03606
Variations of the Similarity Function of TextRank for Automated Summarization
This article presents new alternatives to the similarity function for the TextRank algorithm for automatic summarization of texts. We describe the generalities of the algorithm and the different functions we propose. Some of these variants achieve a signif
arxiv.org
Example
from gensim.summarization.summarizer import summarize
text = '''Rice Pudding - Poem by Alan Alexander Milne
... What is the matter with Mary Jane?
... She's crying with all her might and main,
... And she won't eat her dinner - rice pudding again -
... What is the matter with Mary Jane?
... What is the matter with Mary Jane?
... I've promised her dolls and a daisy-chain,
... And a book about animals - all in vain -
... What is the matter with Mary Jane?
... What is the matter with Mary Jane?
... She's perfectly well, and she hasn't a pain;
... But, look at her, now she's beginning again! -
... What is the matter with Mary Jane?
... What is the matter with Mary Jane?
... I've promised her sweets and a ride in the train,
... And I've begged her to stop for a bit and explain -
... What is the matter with Mary Jane?
... What is the matter with Mary Jane?
... She's perfectly well and she hasn't a pain,
... And it's lovely rice pudding for dinner again!
... What is the matter with Mary Jane?'''
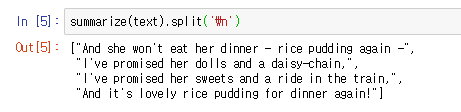
summarize(text).split('\n')- 위의 코드를 실행하면 아래와 같은 결과가 나온다.
Method 소개
summarize
- 결과로 나온 요약 문장은 인풋텍스트 중 가장 대표적인 문장으로 구성되며, 줄 바꿈으로 나뉘어서 문자열로 반환
# 인풋 / 파라미터 / 리턴 값
<< Input >>
- 인풋은 string 타입이여야한다.
- 납득이 될 만한 요약을 위해서는 INPUT_MIN_LENGTH보다 길이가 길어야한다.
- 텍스트는 젠심에 있는 split_sentences 매서드를 사용하여 문장이 나눠질 것이다.
<< Parameters >>
- text (str) : 인풋 텍스트
- ratio (float, optional) : 0과 1사이의 수로써 요약을 위해 선택되는 원본 텍스트 문장의 수의 비율을 결정한다.
- word_coutn (int or None, optional) : 아웃풋에 얼마나 많은 단어를 출력시킬지 정한다. 만약에 ratio와 함께 주어진다면 ratio는 무시된다.
- split (bool, optional) : True인 경우, 문장의 리스트가 리턴된다. 그렇지 않을 경우는 string이 리턴된다.
<< Return >>
- 문자의 리스트 형태
- 문자열
summarize_corpus
- TextRank 알고리즘의 변형을 사용하여 가장 중요한 문서의 코퍼스의 리스트를 받는다.
# 인풋 / 파라미터 / 리턴 값
<< Input >>
- 납득이 될 만한 요약을 위해서는 INPUT_MIN_LENGTH보다 길이가 길어야한다.
<< Parameters >>
- corpus (list of list of (int, int) : 주어진 corpus
- ratio (float, optional) : 0과 1사이의 수로써 요약을 위해 선택되는 원본 텍스트 문장의 수의 비율을 결정한다.
<< Return >>
- 문자의 리스트 형태
NLP : Korean Text
발표자료


- 문서 요약의 발표에 사용 된 발표자료
라이브러리 로딩
from gensim.summarization.summarizer import summarize- 필요한 라이브러리 로딩
- 젠심의 summarize 함수를 사용한다.
저장 된 파일 읽기
import json
with open('comment_review.json', 'r', encoding='utf-8-sig') as f:
comment = json.load(f)- 자연어 처리를 하기위해 필요한 코멘트 리뷰 데이터를 load한다.
리뷰가 있는 레스토랑 추출
review_list = []
for key in comment.keys():
if len(comment[key]) > 10:
review_list.append(key)- 총 레스토랑의 갯수 5798개 중에 예약자 리뷰가 있는 레스토랑은 1646개이다.
- 네이버 플레이스 크롤링에 관해서는 다른 글 참고
전처리 함수 만들기
from konlpy.tag import Kkma
kkma = Kkma()
import sys
import os
import re
sys.path.append(os.path.dirname('PyKoSpacing/'))
from pykospacing import spacing
def preprocessing(review):
total_review = ''
#인풋리뷰
for idx in range(len(review)):
r = review[idx]
#하나의 리뷰에서 문장 단위로 자르기
for sentence in kkma.sentences(r):
sentence = re.sub('([a-zA-Z])','',sentence)
sentence = re.sub('[ㄱ-ㅎㅏ-ㅣ]+','',sentence)
sentence = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]','',sentence)
if len(sentence) == 0:
continue
if len(sentence) < 198:
sentence = spacing(sentence)
sentence += '. '
total_review += sentence
return total_review
- 전처리 로직
1> 리뷰는 현재 리스트형태로 들어온다. 한 리뷰씩 추출
2> 리뷰를 kkma.sentences()를 활용하여 다시 문장을 자른다.
3> 문장에서 영어 데이터를 공백으로 변환
4> 문장에서 자음과 모음을 공백으로 변환
5> 문장에서 특수문자 제거
6> 공백인 리뷰데이터 제거
7> 리뷰의 길이가 198이하이면 pykospacing의 spacing을 활용하여 뛰어쓰기 전처리
( 198이상 길이의 문장에 대해서는 warning이 발생하기 때문에 일단 패스한다)
8> 전처리가 끝난 문장의 끝에 '.'를 붙인다.
9> 전처리된 문장의 하나의 변수에 이어 붙인다.
예약자 리뷰 요약하기
key_sentence = {}
for res in review_list:
review = comment[res]
pp = preprocessing(review)
if len(pp.split('.')) < 5:
continue
su = summarize(pp, word_count=20)
su = re.sub('\n', ' ',su)
if len(su) == 0:
continue
key_sentence[res] = su- 리뷰 요약
1> 코맨트가 있는 레스토랑의 리스트를 가져온다.
2> 하나의 레스토랑에 대한 리뷰를 가져온다.
3> 위에서 생성한 전처리과정 거치기
4> '.'를 기준으로 문장을 잘라서 5문장 이하는 패스한다 : 요약이 제대로 진행이 안되기 때문
5> 문장이 콤마로 구분된 문자열을 젠심의 summarize매서드를 사용하여 요약한다.
6> 이때 summarize의 파라미터 값으로 word_count = 20을 준다. 짧은 문장으로 요약하기 위해
7> 결과가 '\n'으로 구분되어 출력되기 때문에 '\n'는 공백으로 바꿔준다.
8> 딕셔너리에 키는 레스토랑의 이름, 값은 요약문을 넣어준다.
파일 저장하기
with open('sum.json','w',encoding='utf-8-sig') as f:
f.write(json.dumps(key_sentence))- 결과는 json형태로 저장한다. 한글이기 때문에 꼭 인코딩은 'utf-8-sig'로 지정한다.
저장 된 파일 불러오기
with open('sum.json','r',encoding='utf-8-sig') as f:
summ = json.load(f)
최종 아웃풋 확인하기
print(sum)- 딕셔너리로 저장 된 결과 확인하기

'Project > TakePicture_GetResult' 카테고리의 다른 글
| [Project] DeepLearning 발표자료(OCR, TFserving) (0) | 2019.05.22 |
|---|---|
| [NLP]자연어처리_감정분석 (2) | 2019.05.20 |
| [NLP]자연어처리_키워드추출 (0) | 2019.05.15 |
| [DL] Seglink + CRNN + Tf_serving 전체 프로세스 (0) | 2019.05.10 |
| [Project] 크래커 프로젝트 전체 흐름 (0) | 2019.05.08 |



